论文阅读:Medley of Sub-Attention Networks for Effective Group Recommendation
发表在 SIGIR ’19
Introduction
因为组群内部成员互相影响,决策需要一个达成共识,故要对成员之间的互动进行评估建模。
以往的算法聚焦pre-defined群组,不适用于ad-hoc(数据量少)
两个层次:每个成员均用一个sub-attention network表示;进而组成混合网络体兼顾个体和群体。
Related work
- 群组推荐:
- 基于内存:
- preference aggregation:聚合所有成员的偏好
- score aggregation:为每个用户计算物品得分,然后聚合分数
- AVG 平均数策略
- the least misery
- 考虑各个成员的disagreement可提升推荐效果
- 基于模型:缺点是针对聚焦pre-defined的组群,可以被视为是向一个用户做推荐(因为组群里的人偏好非常近似)
神经网络应用在推荐上:捕捉非线性的、非平凡的(方程有非零解)关系。
注意力:AGREE也针对pre-defined的组群,使用了
作为整个群组偏好的表征,但这个与我们的设定不符
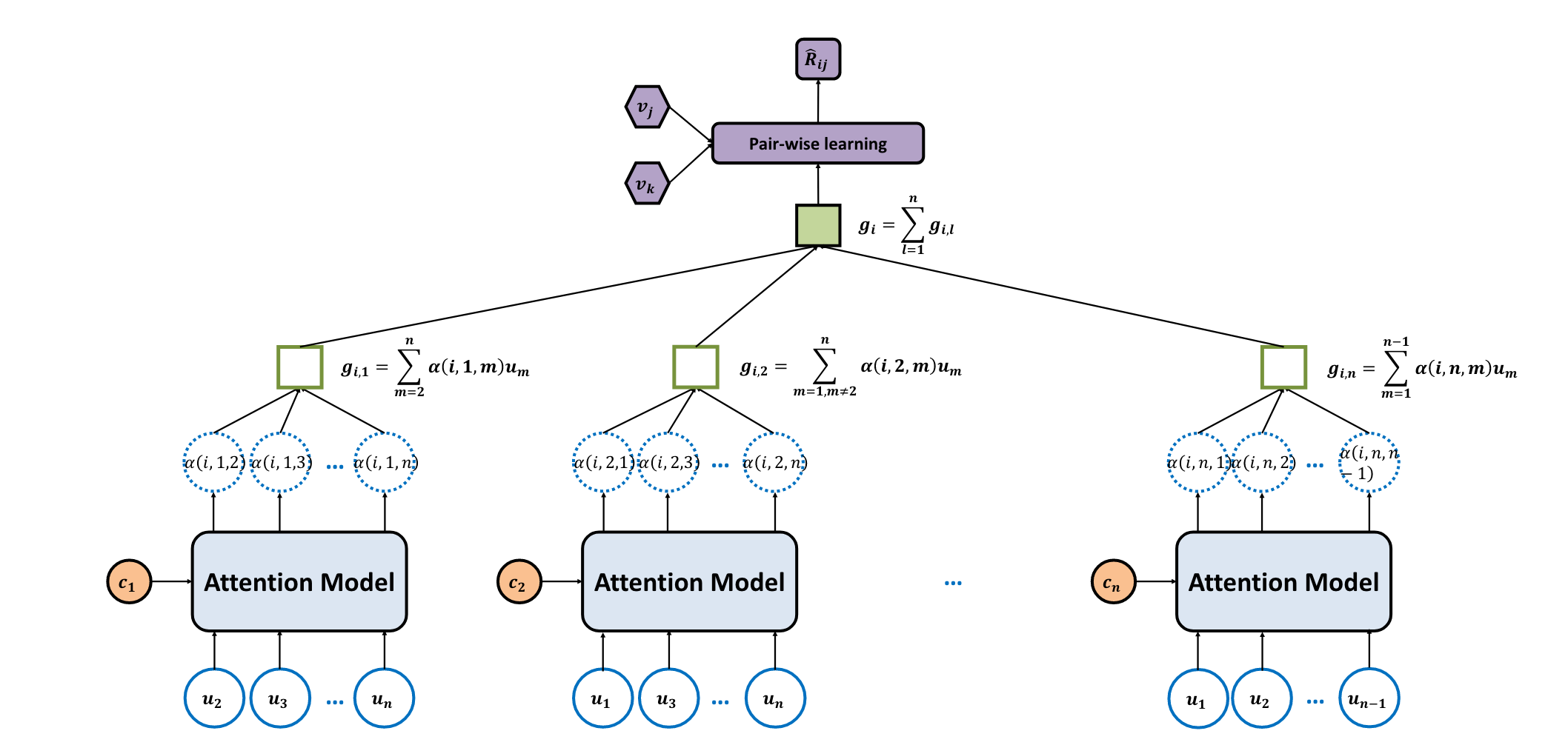
Framework
每次训练组群和一个物品
由 one-hot 做 embedding 生成:
item-latent 物品的表征
user-context 代表注意力子网络的拥有者
user-latent 则是受其影响的其余用户
现有的聚合策略没有考虑到群组的动态变化的复杂度,比如成员影响力在不同的活动上有所不同。使用注意力机制来学习这种动态性。
注意力子网络 一个组群创建 n 个子网络,以用户
为例,其输入是 和 ,分别输出 n-1 个注意力分数 : 论文没有使用激活函数。注意力 query 是子网拥有者
,key 是 再将分数放入 Softmax 函数得到注意力权重
:
然后加权求和得到子网的输出:
也就是注意力的 value 也是
- 混合子网 对所有子网输出求和得到
最终预测分数是 和 (项目向量)的内积。
基于预先的实验,论文没有使用多头注意力。
训练
目标函数
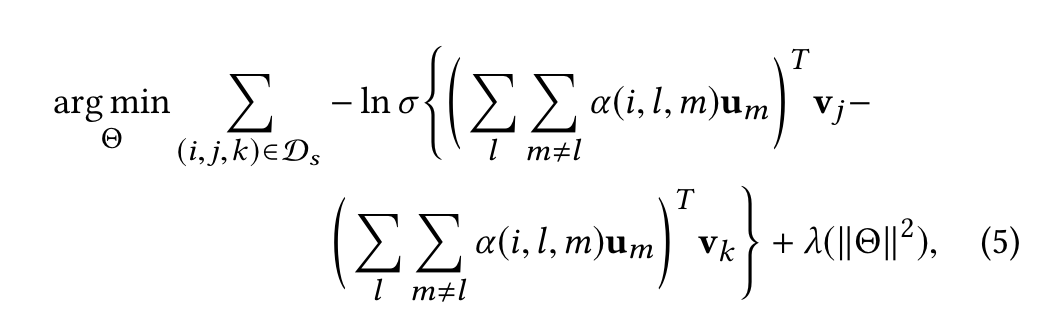
基于 BPR 给出的损失函数。其实是拉大正负样本之间的差距。负样本是指没有被该组群交互过的物品。
训练细节
mini-batch training:将训练集划分子集。是对于batch梯度下降和随机梯度下降的改进。
dropout:概率性让神经元失活,缓解过拟合。
Experiment
与其他7个算法,在不同数据集上进行了比较。
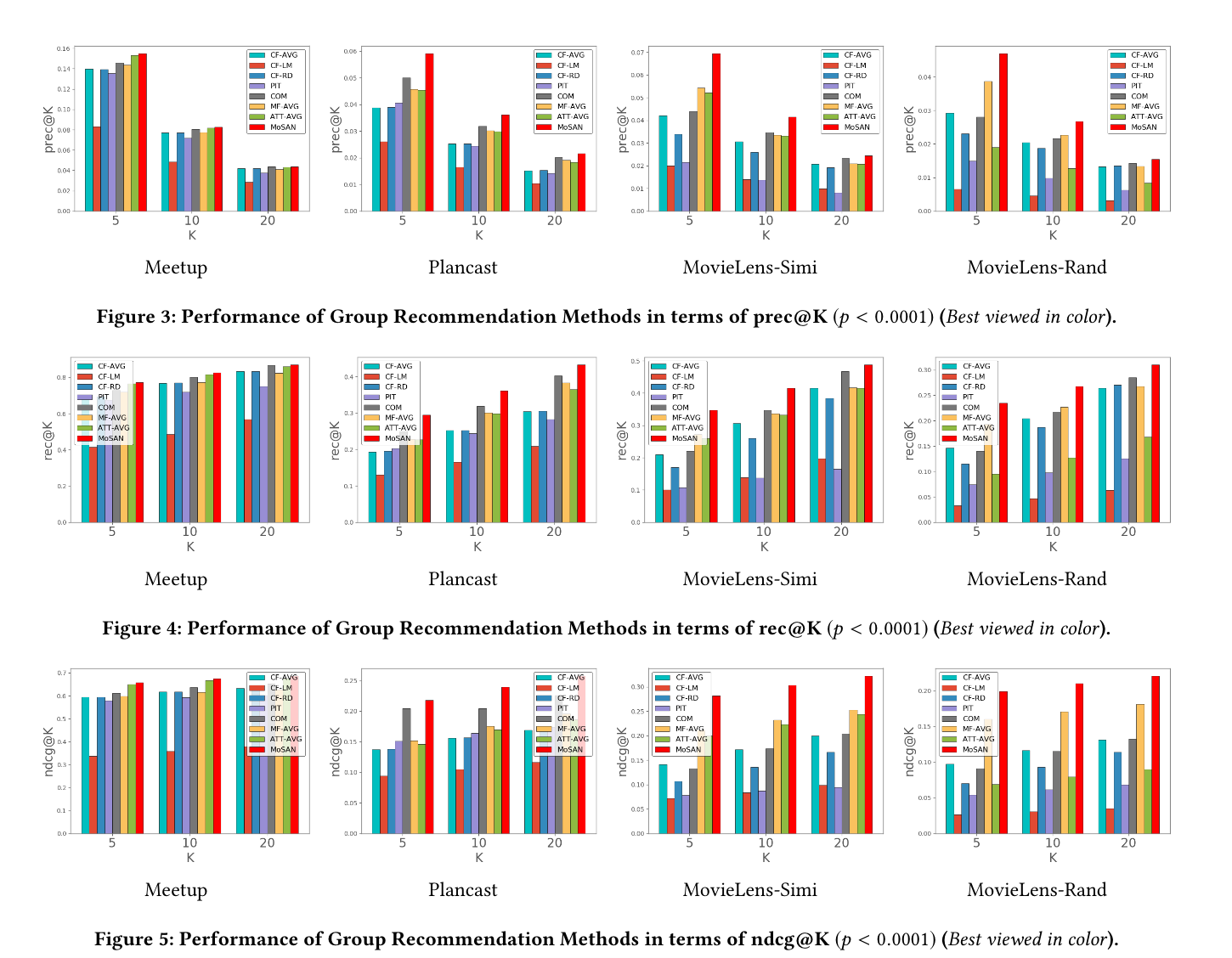
衡量标准:
Precision and recall are classical evaluation metrics in binary classification algorithms and for document retrieval tasks.
Precision准确率是检索出相关结果数与检索出的结果总数的比率,衡量的是检索系统的查准率
Recall@K召回率是指前topK结果中检索出的相关结果数和库中所有的相关结果数的比率,衡量的是检索系统的查全率。