论文阅读:Group Recommendation with Latent Voting Mechanism
Abstract
之前的方法大多是 predsefined 的策略,对于 ad-hoc 的组群(或称 cold-start groups)则无能为力。组群推荐是动态的,每个成员的权重不同,且同一用户在不同组的权重也是不同的。本文针对 Occasional Group Recommendation (OGR),要解决偏好聚合与数据稀疏的问题,故提出 GroupSA,一是将决策视为投票过程,模拟决策的形成;二是使用了 user-item、user-user 的数据,弥补数据稀疏性问题。
Introduction
最近一些工作,如 AGREE 和 SIGR 使用了原始的注意力机制来学习决策过程,但有两个重要问题:
- 忽视了组群成员之间的交互(争论、投票)
- 没有考虑成员的专业知识技能
文中描述了组群的决策过程:先是朋友之间充分交换意见,然后投票选择一些当前话题下的专家,让专家们来决定。
GroupSA使用了自注意力机制。
贡献:
- 注意力网络建模成员的投票方式
- 使用 item aggregation 以及 social aggregation 来提升用户表示,从而解决数据稀疏问题
- 优化的时候 group 和 user 的推荐任务同时(交替)进行,提升训练效果
- 实验数据好
Methodologies
Task Definition
Overview
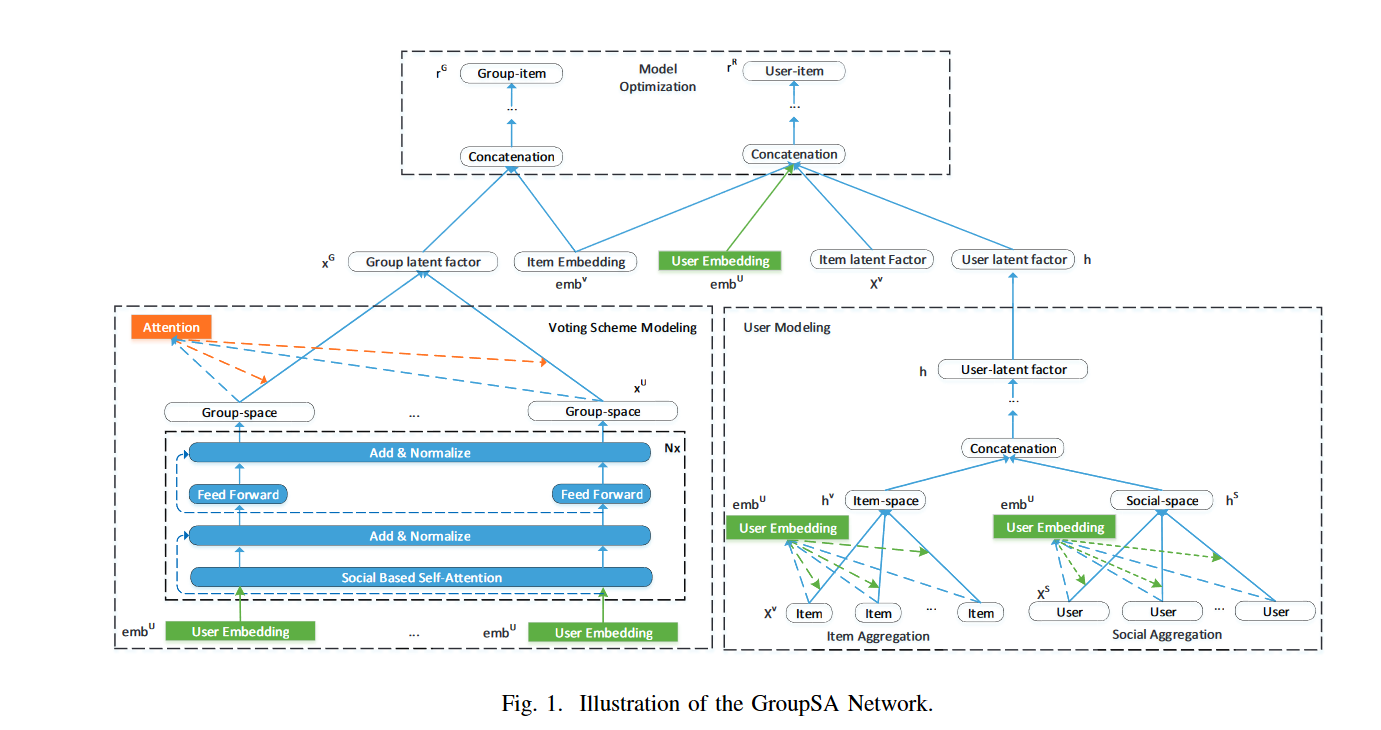
框架总共是三部分:voting scheme modeling, user modeling 以及 the joint optimization technique
Voting Scheme Modeling
通过划分
- 用户对于一个物品的内在感知、看法观点,这在讨论过程中是不变的
- 在其他用户眼中,这个用户能具有多大程度的代表性(类似总统选举)
为了收集到其他用户对于当前用户
多层的叠加可以学习更复杂的特征
网络第一层输入是
定义
在一个用户
现实中人们的决策也会受到朋友间关系的影响,所以增加一个 social bias matrix
其中
注意力:把组群中离主流用户较远的用户的权重降低,也就是减少 outlier 的影响
此处是我认为的 novelty 所在
意思就是没有朋友关系的话我直接忽视他们之间的注意力权重
用户视角下的 sub-group 表示向量,然后第二层是一个 FFN:
这里还用“残差网络+layer normalization”(也就是图中的 Add&Normalize)处理attention+FFN两层的结果,之后网络可以继续叠加,所以每个子层的输出相当于是
这里的网络结构是完全学习的Transformer
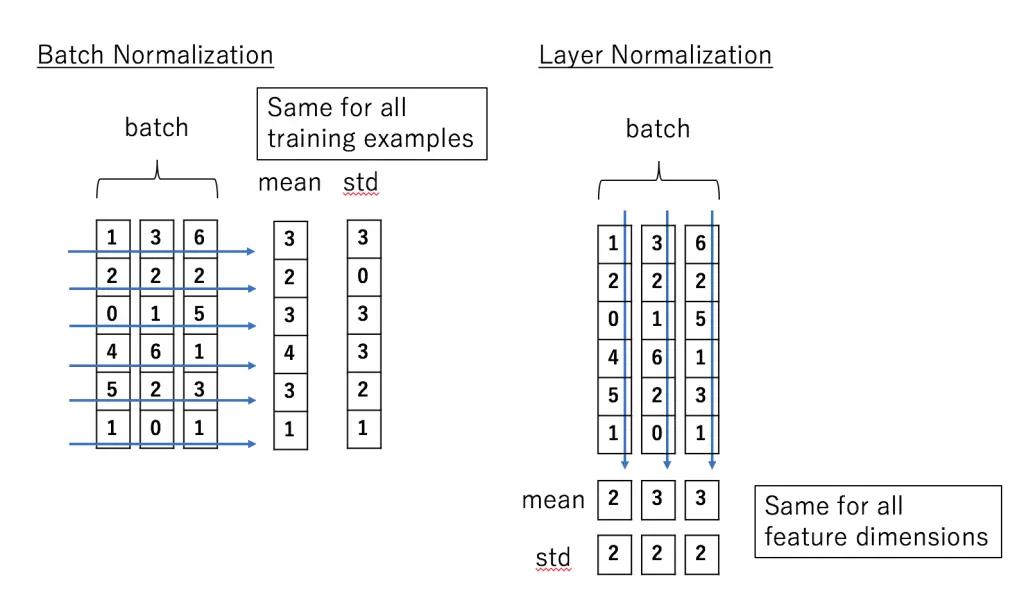
layer normalization 与 batch normalization 的对比如下:
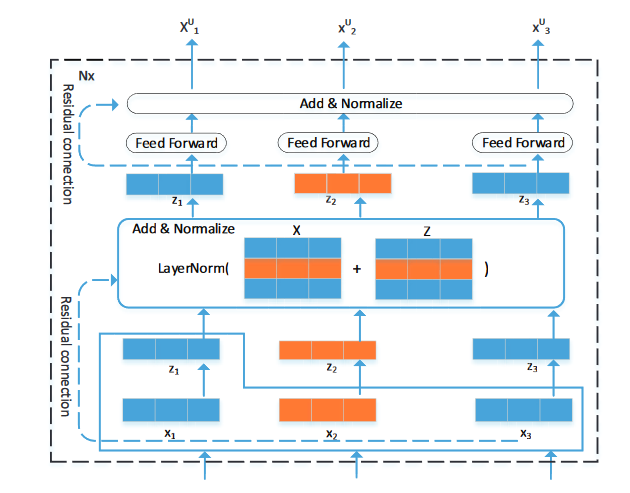
Batch Normalization 的处理对象是对一批样本, Layer Normalization 的处理对象是单个样本。
这样做的好处是可以加速收敛。深度学习有这么一个说法:每一层的数据分布都类似的情况下,网络可以更快地收敛。
这里面究竟怎么normalization的,看图便知,但也要结合代码再看看
每个 sub-group 的偏好意见
其中
User Modeling
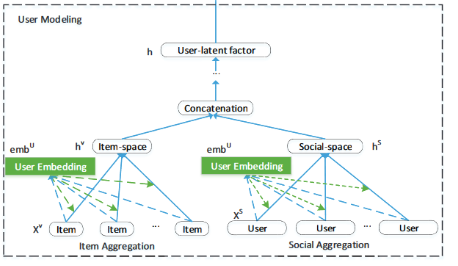
分成两个图结构:user-item和user-user,对应着 item aggregation 和 social aggregation
接下来的事情大同小异了
Item Aggregation
每个user-item 对都给一个权重,
Social Aggregation
和之前的一样,就是用社交朋友的向量表示这个目标用户:
Final User Latent Factor
由于 item space 和 social space 的语义不同,不能直接合并,于是用户隐向量表示需要用网络来转一转:
Model Optimization
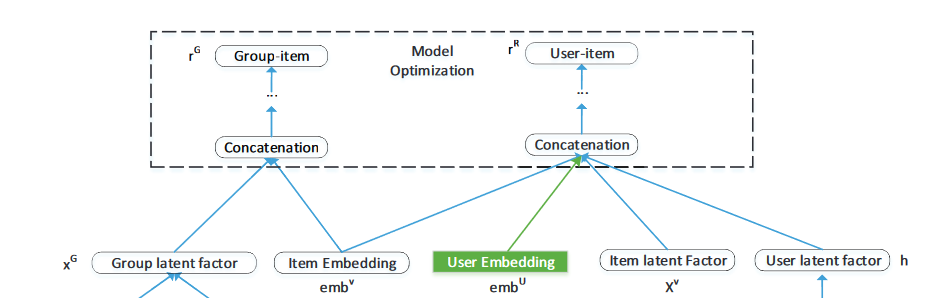
首先这里因为同时获得了用户的表征向量,所以不仅能做组群推荐,顺便也可以做个人的推荐任务
把目标的组群和物品的向量concat在一起,再过几层网络:
然后是 pair-wise 损失函数:
其中
得到的
此外,之前得到用户隐向量
损失函数:
训练的时候先优化
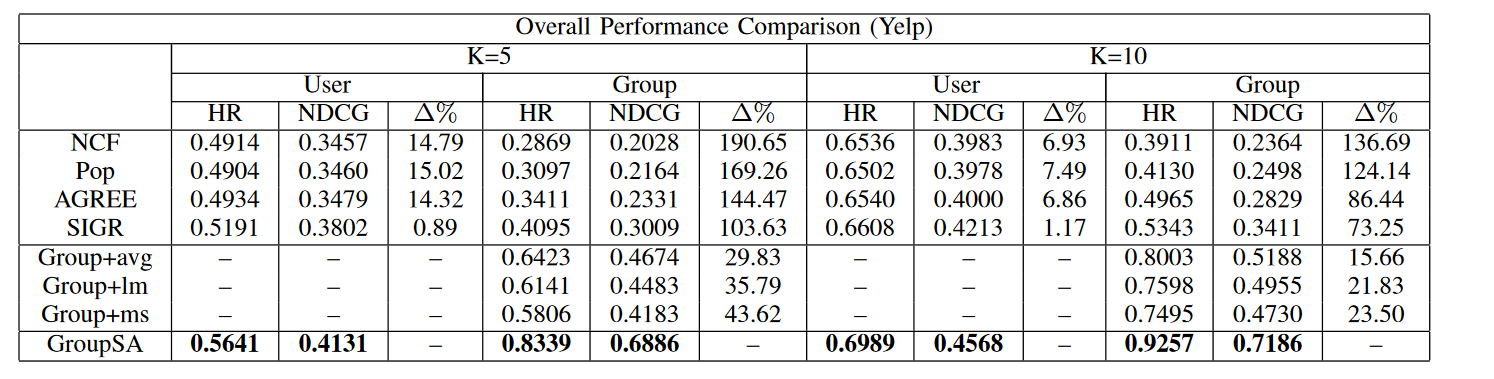
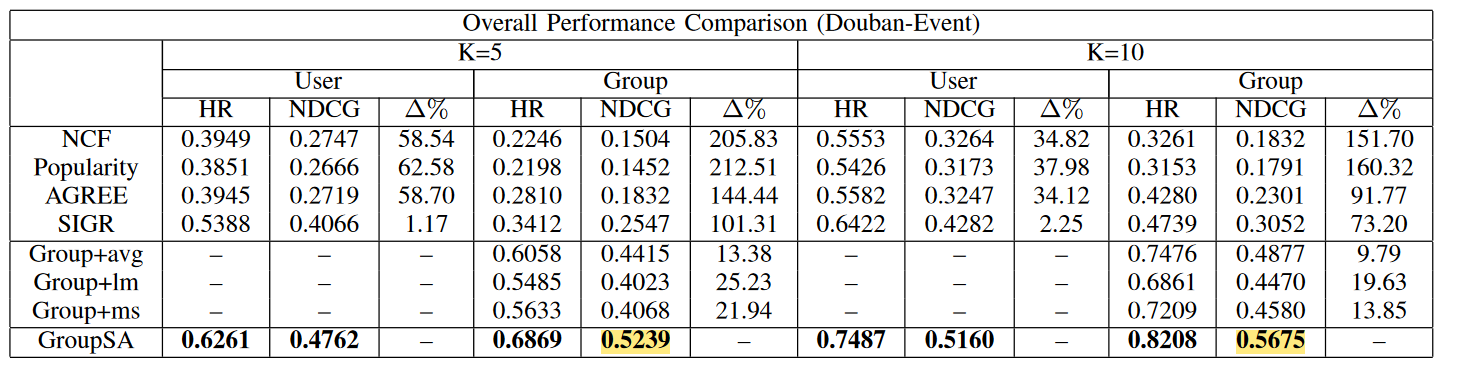
Experiment
两个数据集 Yelp 和 Douban-Event